
Stream Computing
AMD didn't spend a lot of time talking about its general compute capabilities – it's as if it's very much secondary to the graphics mode of operation, but I'm not quite sure why because the architecture has a lot of potential to deliver some great general computing performance.AMD has beefed up the chip's compute capabilities quite significantly with the increased stream processor count – at peak, the Radeon HD 4850 has one teraFLOPS of horsepower on tap, while the Radeon HD 4870 peaks at 1.2 teraFLOPS. All things considered, that's a lot of throughput—it's higher than anything Nvidia can offer at the moment—and it'll be interesting to see how and when AMD starts to utilise the GPU's horsepower in non-graphics tasks.
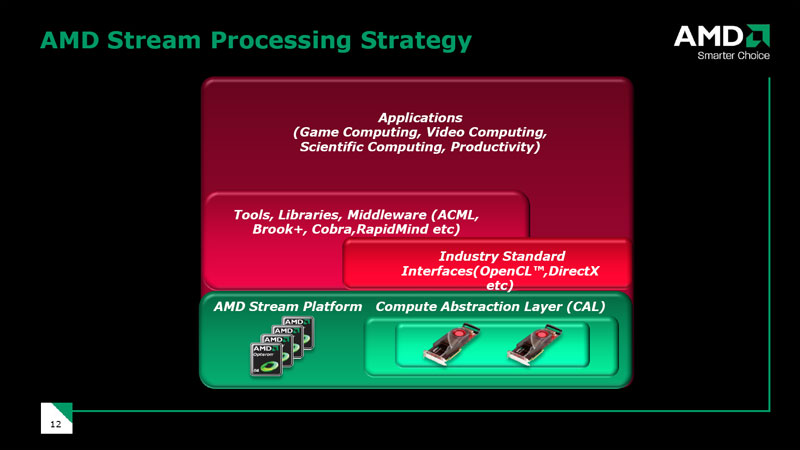
Stream computing applications don't run natively on AMD's hardware – instead, they're run through a software layer that's known as the Accelerated Computing Software Stack, which includes both compile-time and run-time components. The compile-time component includes a bunch of C/C++ compilers, along with a selection of tools, libraries and middleware like Brook+, ACML (Accelerated Computing Math Library), Cobra, Havok, Peakstream and RapidMind.
AMD refers to its run-time component as the Compute Abstraction Layer (CAL), which acts as a go between for the developer and the array of data parallel processors. It's not quite that simple though, because CAL is designed to allow developers to write code that runs on both AMD's multi-core CPUs and ATI Radeon GPUs – that means there's a need for another hardware abstraction layer, known as CTM, which is basically an assembler interface that sits in between the GPU and CAL.

Click to enlarge
The company doesn't really talk about CTM a great deal these days and prefers to talk about CAL as the best solution, leaving CTM as a fairly transparent layer in the software stack. We think this is the right way to go if AMD's stream computing initiatives are going to hit widespread adoption in consumer applications – assembler really isn't the best way to go about things in this day and age.
Industry standard APIs are also tacked onto the Compute Abstraction Layer too, which means that DirectX, OpenGL and also OpenCL communicate with the hardware at this level. This is where the Catalyst driver suite sits and works with the APIs to ensure that the GPU's resources are as fully utilised as possible at any given point in time.
In terms of hardware support, there have also been a few notable changes too. Double precision is probably the biggest and it has been expanded from the Radeon HD 3800 series and is now fully exposed and complies with IEEE 754 precision requirements. Workloads requiring double precision are handled using all five stream processors in a shader processing unit with the four 'thin' units handle a significant portion of the process, while the 'fat' unit handles the accumulation process. What's more, each SIMD core must either be in single or double precision mode at any given time. We asked about switching between single and double precision tasks and were told that reordering is possible, but it comes with some quite serious performance penalties.


Click to enlarge
AMD has also improved the chip's vectored I/O performance (random reading and writing) by a factor of two. RV770 can run scatter and gather ops at a rate of 16 64-bit or eight 128-bit exports per clock. Scatter/gather is great for massively threaded computing, as it can help to conserve bandwidth because the application is only making one vectored memory read or write instead of many ordinary memory accesses.
The introduction of a 16KB local data share (that's separate from the texture cache) for each SIMD unit allows data to be shared between threads or stream processors, while there's also a global data share that all SIMDs can access, meaning data can be shared right across the GPU.
Finally, AMD also talked about the chip's ability to handle fast integer bit shift operations, which are incredibly important for video processing, encoding and compression algorithms. The company says it has been implemented into all 800 of RV770's stream processing units and means that this type of task is more than an order of magnitude faster than the Radeon HD 3800-series cards.
With all of this in mind, there have been a few hints of consumer-class applications coming, but we haven't seen any of them running yet. AMD says that Adobe, Cyberlink and Havok will be using the RV770 to accelerate tasks ranging from photo editing and video transcoding to in-game physics simulations – I guess it's going to be a game of wait and see how things turn out in the long run. What we'd love to see though is for AMD to start working with some of the smaller startups – you'd be amazed at the number of small companies working on CUDA-accelerated applications and we'd really like to see the same happening for AMD's ATI Radeon GPUs as well.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.